
Paper Reading:Robot learning 3
我要和他们站在一起。
RL-BASED DRONE PAPER READING
Large-scale RL Exploration#
特权强化学习与注意力图网络,图稀疏化适配大规模场景
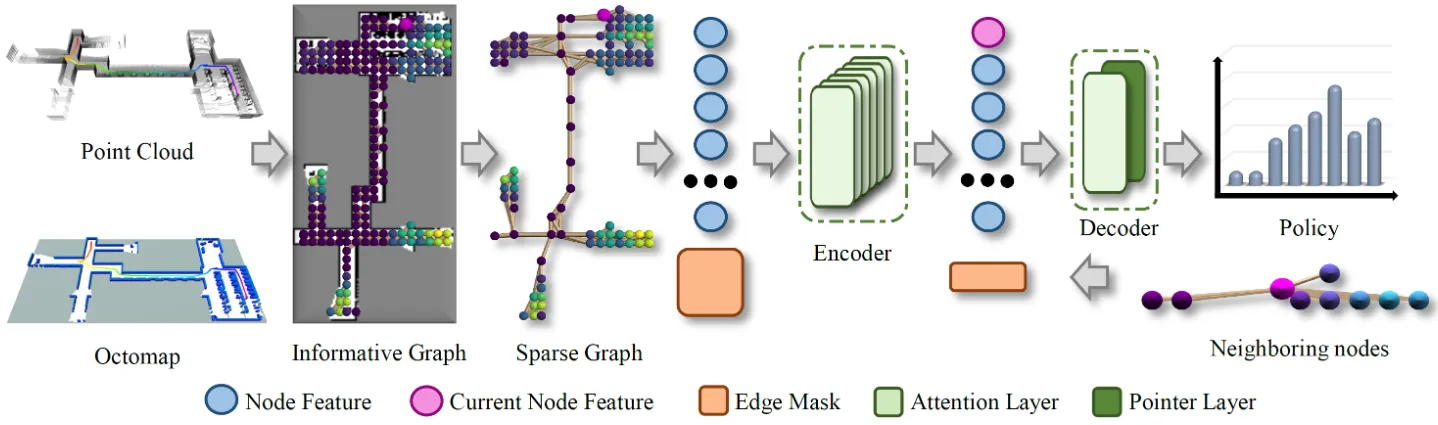 面向大规模环境的深度强化学习探索规划器,采用特权学习让评论家网络访问真实环境信息以精准评估策略,结合注意力图网络捕捉多尺度空间依赖关系,通过图稀疏化算法使小场景训练模型可直接用于大规模环境,仿真与实机验证其路径长度、耗时与规划速度均优于TARE等前沿方法。
面向大规模环境的深度强化学习探索规划器,采用特权学习让评论家网络访问真实环境信息以精准评估策略,结合注意力图网络捕捉多尺度空间依赖关系,通过图稀疏化算法使小场景训练模型可直接用于大规模环境,仿真与实机验证其路径长度、耗时与规划速度均优于TARE等前沿方法。
Agile Flight from Pixels#
非对称演员-评论家+门边缘视觉抽象+无状态估计像素控制
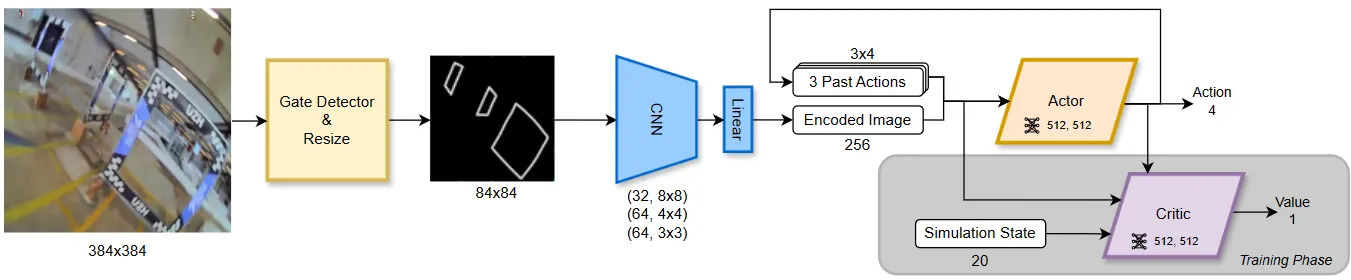 该文实现首个无显式状态估计的四旋翼视觉敏捷飞行系统,采用非对称演员-评论家框架让评论家获取特权状态信息提升训练效果,以赛道门内边缘作为视觉抽象简化像素级RL训练,搭配SwinTransformer门检测器,仅靠机载摄像头视频流即可实现最高40km/h、2g加速度的竞速飞行,完成零样本仿真到现实迁移。
该文实现首个无显式状态估计的四旋翼视觉敏捷飞行系统,采用非对称演员-评论家框架让评论家获取特权状态信息提升训练效果,以赛道门内边缘作为视觉抽象简化像素级RL训练,搭配SwinTransformer门检测器,仅靠机载摄像头视频流即可实现最高40km/h、2g加速度的竞速飞行,完成零样本仿真到现实迁移。
HOLA-Drone#
超图开放式学习+零样本协同,适配未知队友无人机追捕
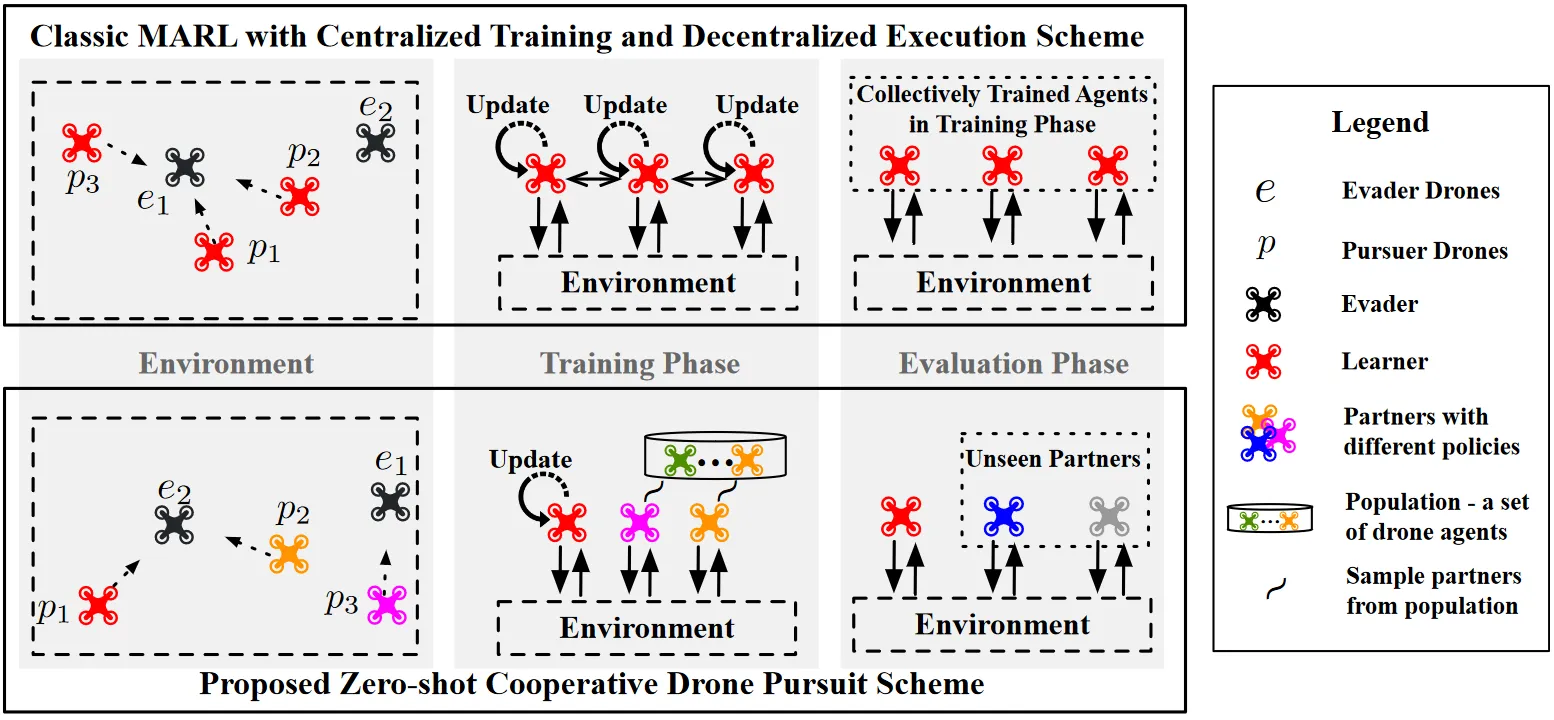 将多无人机协同追捕建模为零样本协同问题,提出HOLA-Drone超图开放式学习算法,以超图形式化建模多智能体协同交互关系,自适应动态调整学习目标强化与未知队友的协作能力,仿真与实机实验证明其在同质、异质未知队友场景下的追捕成功率与效率显著优于自博弈、种群训练等基线方法。
将多无人机协同追捕建模为零样本协同问题,提出HOLA-Drone超图开放式学习算法,以超图形式化建模多智能体协同交互关系,自适应动态调整学习目标强化与未知队友的协作能力,仿真与实机实验证明其在同质、异质未知队友场景下的追捕成功率与效率显著优于自博弈、种群训练等基线方法。
OmniDrones#
GPU并行仿真+多机型多任务,无人机强化学习专用平台
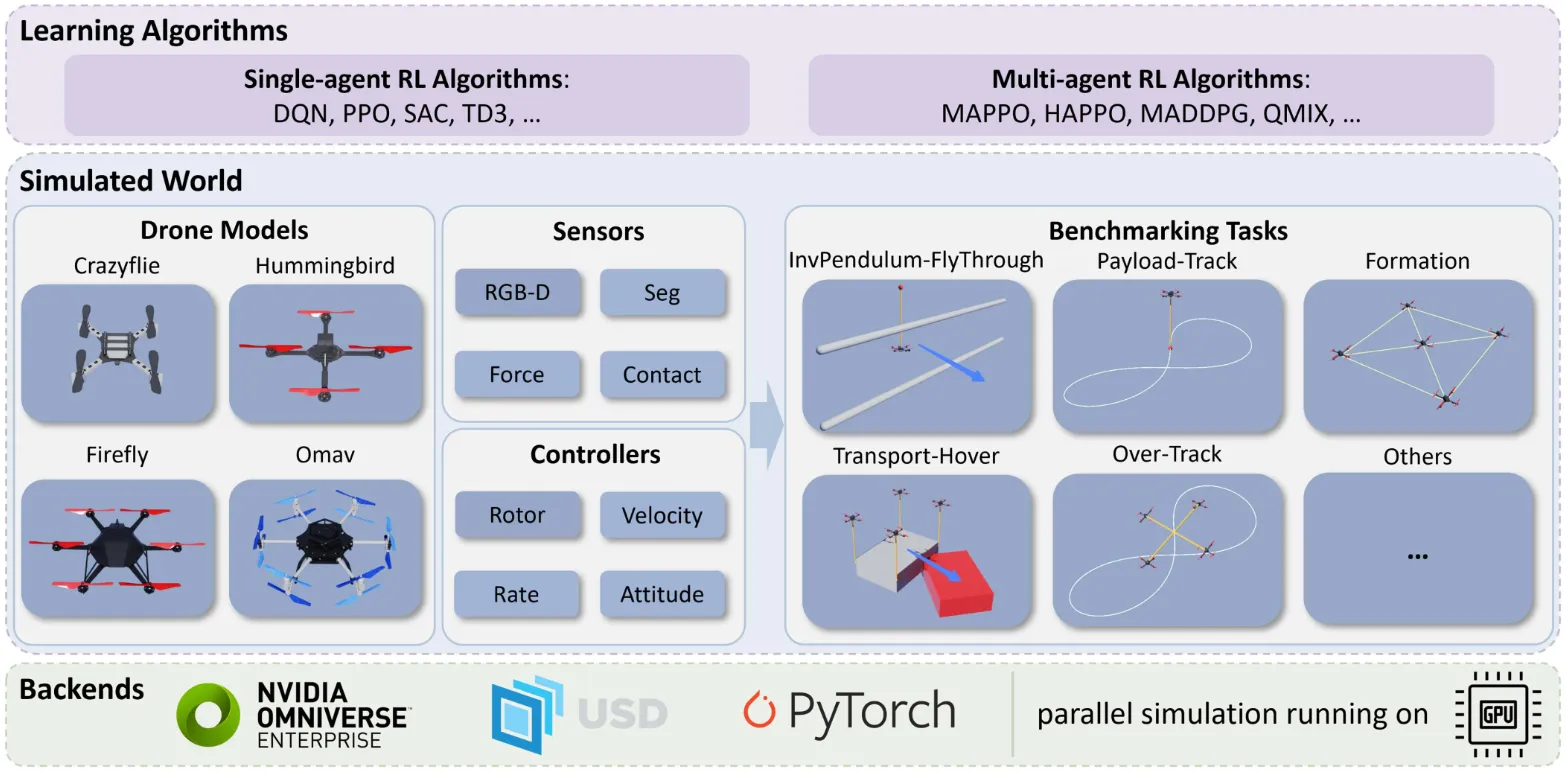 基于NVIDIA Omniverse Isaac Sim构建OmniDrones无人机强化学习平台,以PyTorch实现动力学GPU并行计算提升采样效率,支持4类机型、5种传感器、4种控制模式与10余项基准任务,兼容主流单/多智能体强化学习算法,为无人机控制学习提供高效可扩展、易定制的仿真与评测环境。
基于NVIDIA Omniverse Isaac Sim构建OmniDrones无人机强化学习平台,以PyTorch实现动力学GPU并行计算提升采样效率,支持4类机型、5种传感器、4种控制模式与10余项基准任务,兼容主流单/多智能体强化学习算法,为无人机控制学习提供高效可扩展、易定制的仿真与评测环境。
Multi-UAV Pursuit-Evasion#
逃逸预测网络+自适应环境生成+两阶段奖励,未知环境追逃
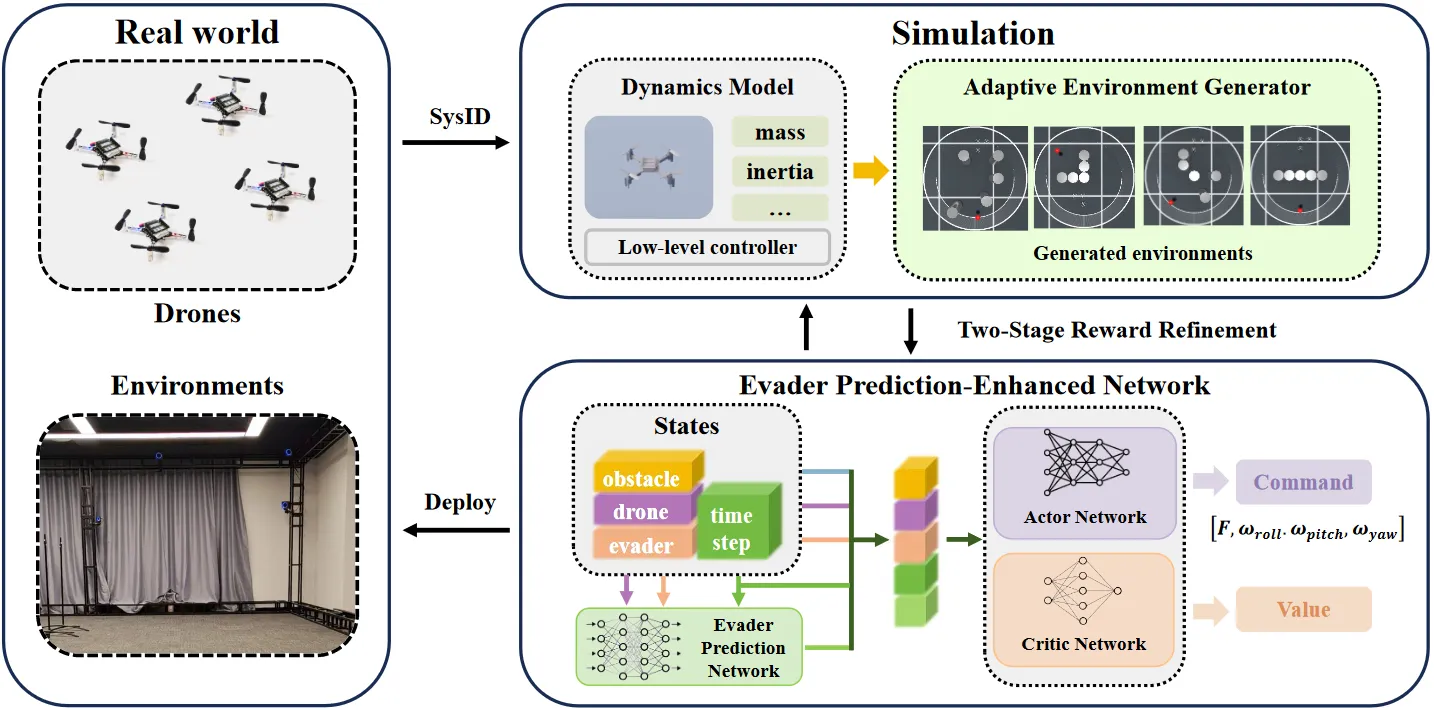 未知环境多无人机追逃问题,提出逃逸者预测增强网络处理部分可观测性,结合自适应环境生成器提升策略泛化与样本效率,通过两阶段奖励细化保证指令平滑可部署,仿真中在未知场景实现100%捕获率且优于所有基线,首次将输出总推力与机体角速度的RL策略零样本部署到真实四旋翼完成追逃任务。
未知环境多无人机追逃问题,提出逃逸者预测增强网络处理部分可观测性,结合自适应环境生成器提升策略泛化与样本效率,通过两阶段奖励细化保证指令平滑可部署,仿真中在未知场景实现100%捕获率且优于所有基线,首次将输出总推力与机体角速度的RL策略零样本部署到真实四旋翼完成追逃任务。
PKCC#
学习修正运动学+权重分配MPC,空中操作臂高精度协同控制
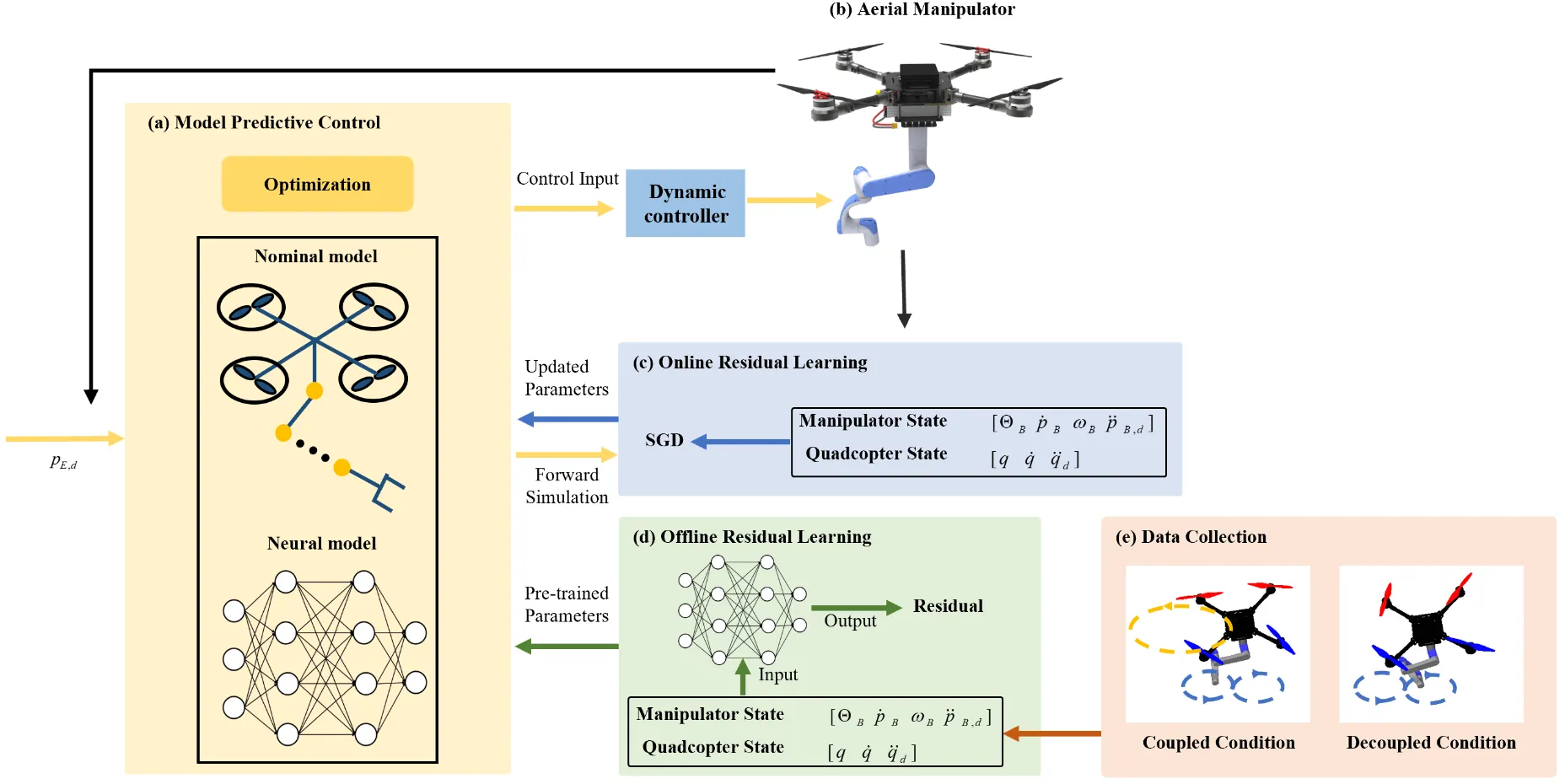 对空中操作臂运动学控制精度低、运动分配困难的问题,提出预测运动协同控制方法,构建融入闭环动力学与在线残差学习的修正运动学模型提升建模精度,设计权重分配模型预测控制协调无人机与机械臂运动策略,实验表明轨迹跟踪精度提升59.6%,可完成复杂轨迹与移动目标跟踪任务。
对空中操作臂运动学控制精度低、运动分配困难的问题,提出预测运动协同控制方法,构建融入闭环动力学与在线残差学习的修正运动学模型提升建模精度,设计权重分配模型预测控制协调无人机与机械臂运动策略,实验表明轨迹跟踪精度提升59.6%,可完成复杂轨迹与移动目标跟踪任务。
Pixel Motion#
单目光流+中心流注意力+可微仿真,四旋翼高速避障
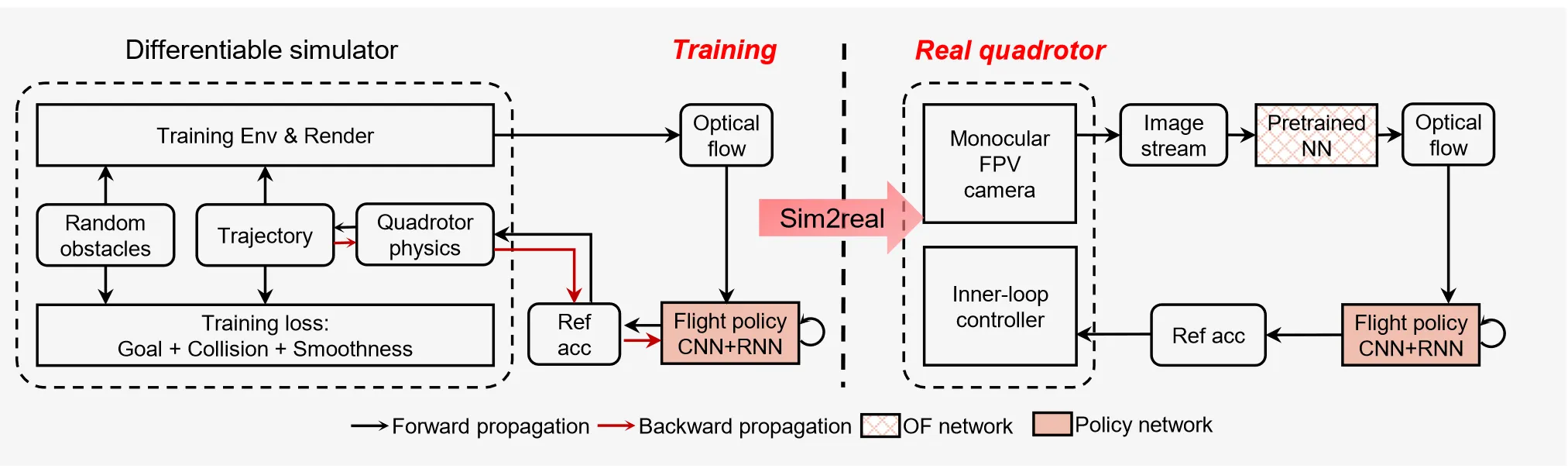 四旋翼单目视觉避障,提出基于光流的端到端学习框架,通过可微仿真完成策略训练,引入中心流注意力与动作引导主动感知机制强化关键视觉信息提取,仅靠单目FPV相机实现最高6m/s的未知复杂环境敏捷避障,具备零样本仿真到现实迁移能力。
四旋翼单目视觉避障,提出基于光流的端到端学习框架,通过可微仿真完成策略训练,引入中心流注意力与动作引导主动感知机制强化关键视觉信息提取,仅靠单目FPV相机实现最高6m/s的未知复杂环境敏捷避障,具备零样本仿真到现实迁移能力。
Simple Flight#
PPO+五维关键设计,四旋翼零样本sim2real迁移控制
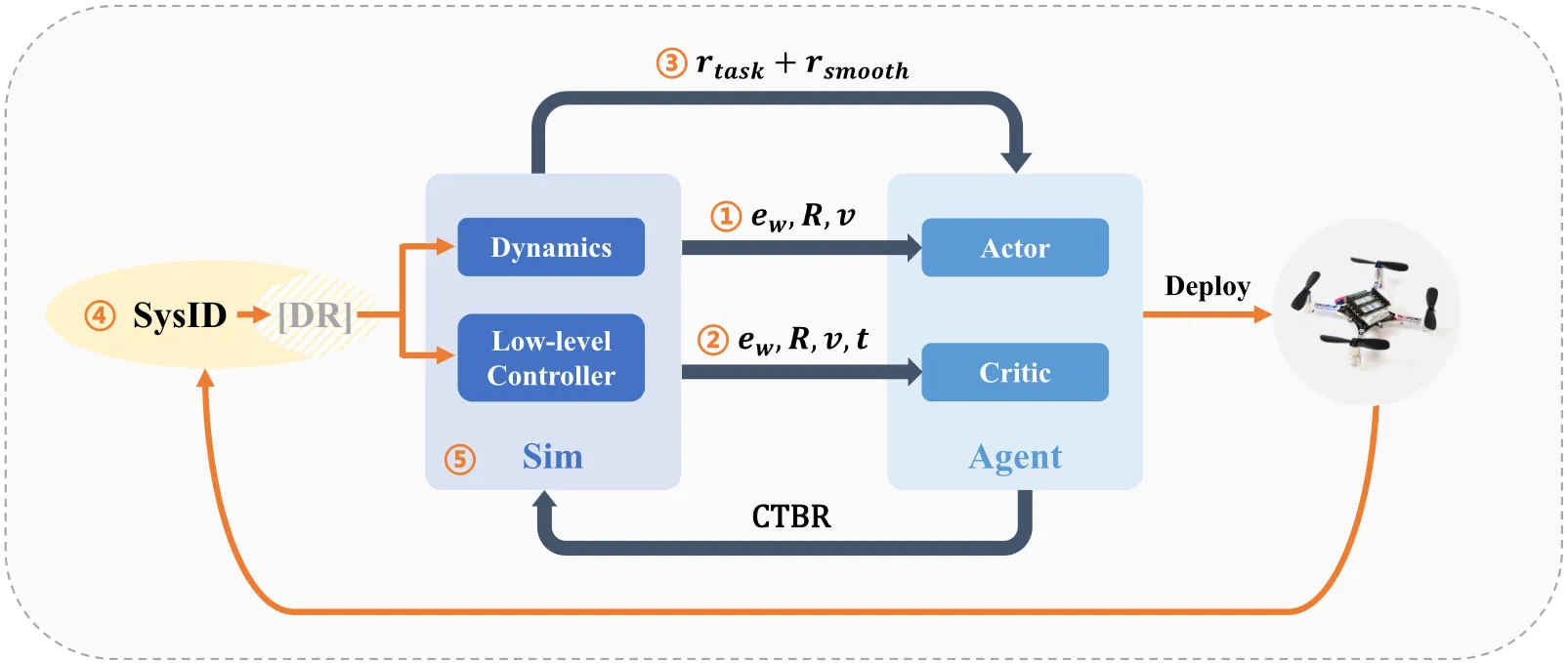 提炼出四旋翼强化学习零样本部署的五大核心要素,基于PPO算法构建SimpleFlight框架,优化观测输入、奖励平滑、系统辨识与选择性域随机化、大批次训练策略,在纳米无人机上轨迹跟踪误差降低超50%,可稳定跟踪平滑与不可行轨迹并跨平台泛化。
提炼出四旋翼强化学习零样本部署的五大核心要素,基于PPO算法构建SimpleFlight框架,优化观测输入、奖励平滑、系统辨识与选择性域随机化、大批次训练策略,在纳米无人机上轨迹跟踪误差降低超50%,可稳定跟踪平滑与不可行轨迹并跨平台泛化。
Whole-Body Control Gap#
RL+观测蒸馏+知情重置,像素到动作窄缝全身穿越
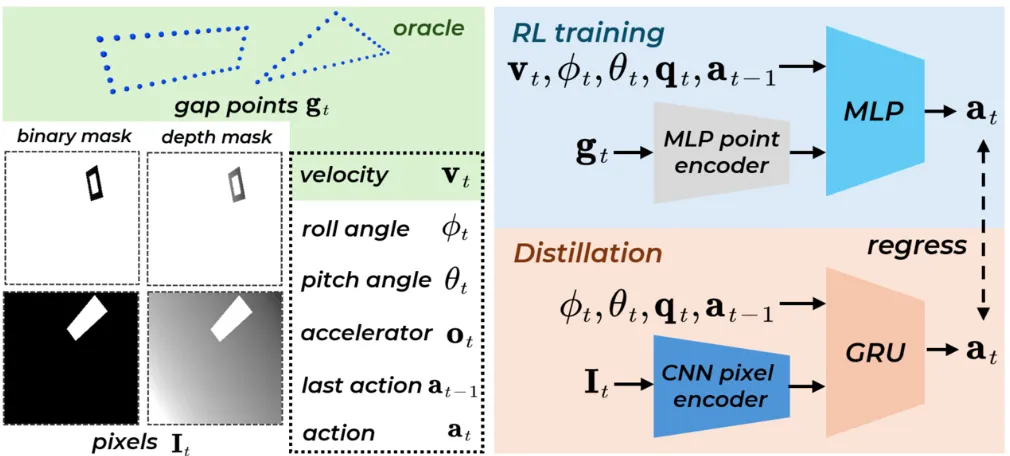 四旋翼从像素到动作的端到端窄缝全身控制,采用模型无关强化学习生成低维点云策略,通过在线观测蒸馏迁移到高维像素输入,提出知情重置缓解稀疏探索难题,无需手工课程即可完成多几何形态、大姿态的机身级窄缝穿越。
四旋翼从像素到动作的端到端窄缝全身控制,采用模型无关强化学习生成低维点云策略,通过在线观测蒸馏迁移到高维像素输入,提出知情重置缓解稀疏探索难题,无需手工课程即可完成多几何形态、大姿态的机身级窄缝穿越。
YOPO#
单阶段规划+引导学习+运动基元,四旋翼无地图实时轨迹生成
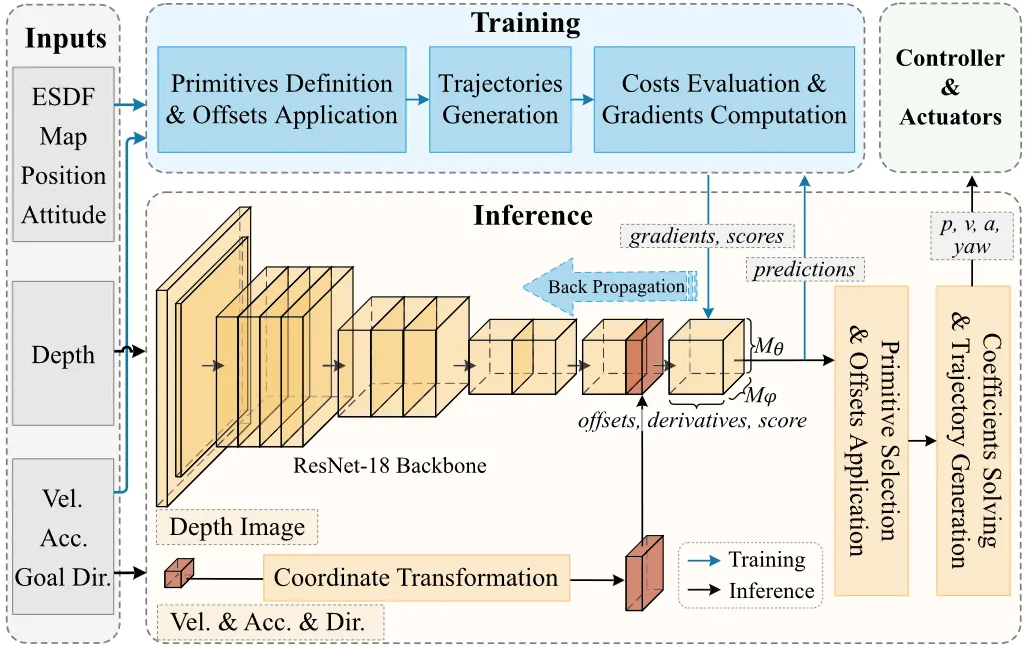 四旋翼单阶段学习规划器YOPO,将感知、路径搜索、轨迹优化融合为单一网络,以运动基元覆盖规划解空间,创新引导学习方法利用数值梯度训练网络,推理时延仅1.6ms,仿真与实机实验中实现复杂森林环境高速安全飞行,性能优于传统梯度优化方法。
四旋翼单阶段学习规划器YOPO,将感知、路径搜索、轨迹优化融合为单一网络,以运动基元覆盖规划解空间,创新引导学习方法利用数值梯度训练网络,推理时延仅1.6ms,仿真与实机实验中实现复杂森林环境高速安全飞行,性能优于传统梯度优化方法。